27-Sep-2022 by Damian Maclennan
Better operations with structured logging

The single best thing you can do to improve your operations and visibility into your systems?
Structured Logging.
In the “old days”, we logged lines of text into a text file. Some standard ways of formatting emerged and tools came about which could slurp up your files into a database for some analysis later. It was usually after the fact, and OK for post-mortems, but not a great insight into your running system.
Some applications logged directly into a database table, usually with some home-grown logging system. This let us decorate logs with some other metadata, maybe a user ID, or the request path. But we were limited by how much we were prepared to add to the table schemas.
As we started to build more distributed systems, we could either log into a central database (and have the same schema issues), or worse, log into text files on each server.
I know of teams operating microservices who would need to SSH into multiple webservers and Grep log files to find errors.
In the past few years though a solution to this has become more widespread. Structured logging refers to logging both the message or message template, as well as attached properties.
With this structuring, and an appropriate storage mechanism, logs can be filtered out by attached properties such as a request id, or an order id. But these properties can also be selected as points of data without having to grep the lines of a log file.
Where this gets really powerful, and essential in a distributed system, is aggregating all these logs into a purpose build log database such as Seq from Datalust.
Not only can you trace transactions across multiple systems using some kind of correlation identifier, you can query the properties of your logs to provide visualisations of the health of your systems.
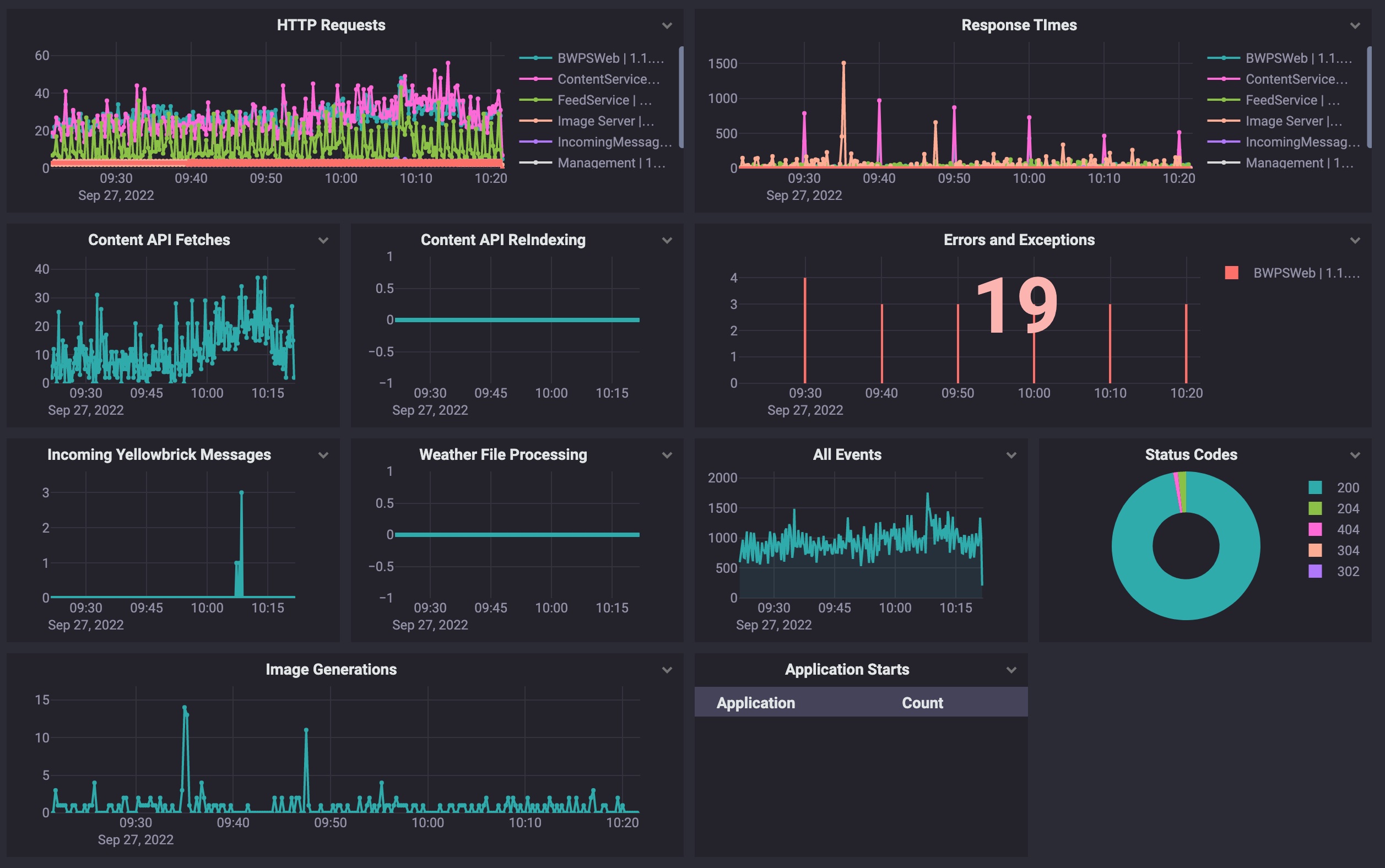
If you’re not using Structured Logging in your systems you’re missing out an opportunity for a very low cost and effort way to get observability into your system.